缴费项目主体功能完成的差不多了,写前端JS写的都快吐了,把所有的通用的代码封装在一个文件里差不多有1500行。接下去应该主要是Bug修正和性能优化了。性能优化方面,数据库访问效率是重要的环节,使用ORM遇到的一个很常见的是 “N+1”问题,自然Django也不例外。
N+1问题
以一个简单的例子说明。假设你有一个包含若干辆汽车(Car)的集合(数据库记录),每个车辆有若干个轮胎(wheel)。也就是说,汽车和轮胎是一个一对多的关系。
如果你需要,迭代出所有的汽车信息,并且对于每辆汽车打印它的轮胎信息。则可以使用以下SQL实现:
然后对于每辆车,使用以下的SQL语句:
1
| SELECT * FROM wheel WHERE CarId = ?
|
也就是说,在此过程中进行了N+1次数据库查询操作,其中N为汽车的数目。
但是,另一种更为效率的方式,在查出所有车辆信息后,直接查询所有的轮胎的记录,在内存中查找之间的联系。
该例子来自于 https://stackoverflow.com/questions/97197/what-is-n1-select-query-issue 。
在Django中可以使用 select_related和 prefetch_related 查询API解决这个问题。标准查询如下:
1
2
3
4
|
e = Entry.objects.get(id=5)
b = e.blog
|
如果使用 select_related 函数后:
1
2
3
4
5
|
e = Entry.objects.select_related('blog').get(id=5)
b = e.blog
|
表定义
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
| class Organization(models.Model):
name = models.CharField(max_length=100)
remark = models.TextField(max_length=500, null=True, blank=True)
class Enterprise(models.Model):
name = models.CharField(verbose_name='名称', max_length=100)
catalog = models.CharField(verbose_name='分类', max_length=10, null=True, blank=True)
address = models.CharField(verbose_name='地址', max_length=100, null=True, blank=True)
organization = models.ForeignKey(Organization, on_delete=models.CASCADE, verbose_name='组织', null=True, blank=True)
remark = models.TextField(verbose_name='备注', max_length=500, null=True, blank=True)
price = models.DecimalField(verbose_name='单价', max_digits=15, decimal_places=3, default=0)
unit = models.CharField(verbose_name='单位', max_length=10, null=True, blank=True)
charge_type = models.CharField(verbose_name='收费类型', max_length=10, choices=ChargeType.choices)
objects = EnterpriseManager()
class Bill(models.Model):
enterprise = models.ForeignKey(Enterprise, verbose_name='企业', on_delete=models.CASCADE)
year = models.IntegerField(verbose_name='年份')
month = models.IntegerField(verbose_name='月份')
price = models.DecimalField(verbose_name='单价', max_digits=15, decimal_places=3)
unit = models.CharField(verbose_name='单位', max_length=10)
amount = models.DecimalField(verbose_name='用量', max_digits=15, decimal_places=3, default=0)
total = models.DecimalField(verbose_name='应收金额', max_digits=15, decimal_places=2)
|
数据库有 组织(Organization)、企业(Enterprise)和账单(Bill)三张表,它们的关系如下:
- 每个企业可以隶属于一个组织,也可以不隶属于任何一个组织
- 每个企业可以有按年缴费和按月缴费两种缴费类型,使用charge_type区分
- 每个企业在同一月份或者同一年度(由缴费类型决定)只能有一条唯一的记录,该特性由业务层限制
测试代码
测试场景:获取所有账单数据,并且需要包括他们的企业基本信息,如名称、地址等。
测试是否使用 select_related 函数对查询耗时的影响。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
| def test_normal():
t1 = time.time()
el = []
bill_qs = models.Bill.objects.all()
for bill in bill_qs:
el.append(bill.enterprise)
t2 = time.time()
print('Normal {0}'.format(t2 - t1))
def test_select_related():
t1 = time.time()
el = []
bill_qs = models.Bill.objects.all().select_related('enterprise')
for bill in bill_qs:
el.append(bill.enterprise)
t2 = time.time()
print('Select {0}'.format(t2 - t2))
|
规模定义
假设 N 表示按年缴费和按月缴费的企业数目,即总企业数为 2N,则一年Bill账单总数为 12 x N + N = 13N,即测试代码中 models.Bill.objects.all().count() 返回的值。
结果
以下是在Windows 10 64位 / Python3.5 / Django1.10.3 / 内存数据库 所测的数据:
| N= | 1 | 10 | 100 | 1000 | 10000 |
| —— | —— | —— | —— | —— |
| Bill Total | 13 | 130 | 1300 | 13000 | 130000 |
| Normal | 0.017008 | 0.157611 | 1.892831 | 16.585734 | 224.317318 |
| Select | 0.004504 | 0.027019 | 0.310722 | 2.259590 | 26.342256 |
| 相比 | 3.7744 | 5.8333 | 6.0917 | 7.3401 | 8.5154 |
使用折线图描绘更为直观:
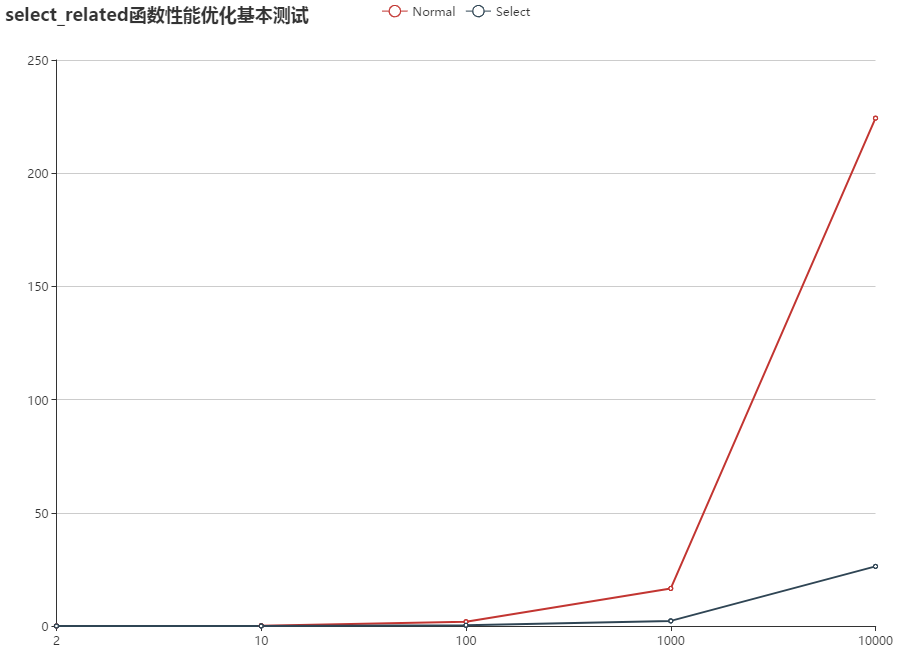
从以上结果可以看成耗时差距随着规模增加越来越大,N大于1000时,两者耗时已不在一个数量级上了。
